เรากำลังเข้าสู่ขั้นตอนสุดท้าย: ให้ AI ตอบคำถามจากเอกสารที่เราอัปโหลด
ในตอนที่แล้ว เราได้:
- โหลดเอกสาร (Load)
- แบ่งข้อมูลเป็นชิ้นเล็ก ๆ (Split)
- แปลงเป็นตัวเลข (Embedding)
- เก็บในฐานข้อมูลเวกเตอร์ (Vector Store)
ในตอนนี้ เราจะ
➡️ สร้างระบบถาม–ตอบ (Q&A System) ที่ทำให้ AI อ่านข้อมูลจากฐานข้อมูลเวกเตอร์ แล้วตอบคำถามของเรา อย่างแม่นยำและสุภาพ
💡 คำศัพท์สำคัญที่ต้องรู้
| คำศัพท์ | ความหมาย |
|---|---|
| Retriever | ตัวค้นหาข้อมูลจาก Vector Store ที่ “ใกล้เคียง” กับคำถามของเรา |
| Chain | โครงสร้างที่เชื่อมทุกอย่างเข้าด้วยกัน (Retriever + Prompt + AI Model + Output) |
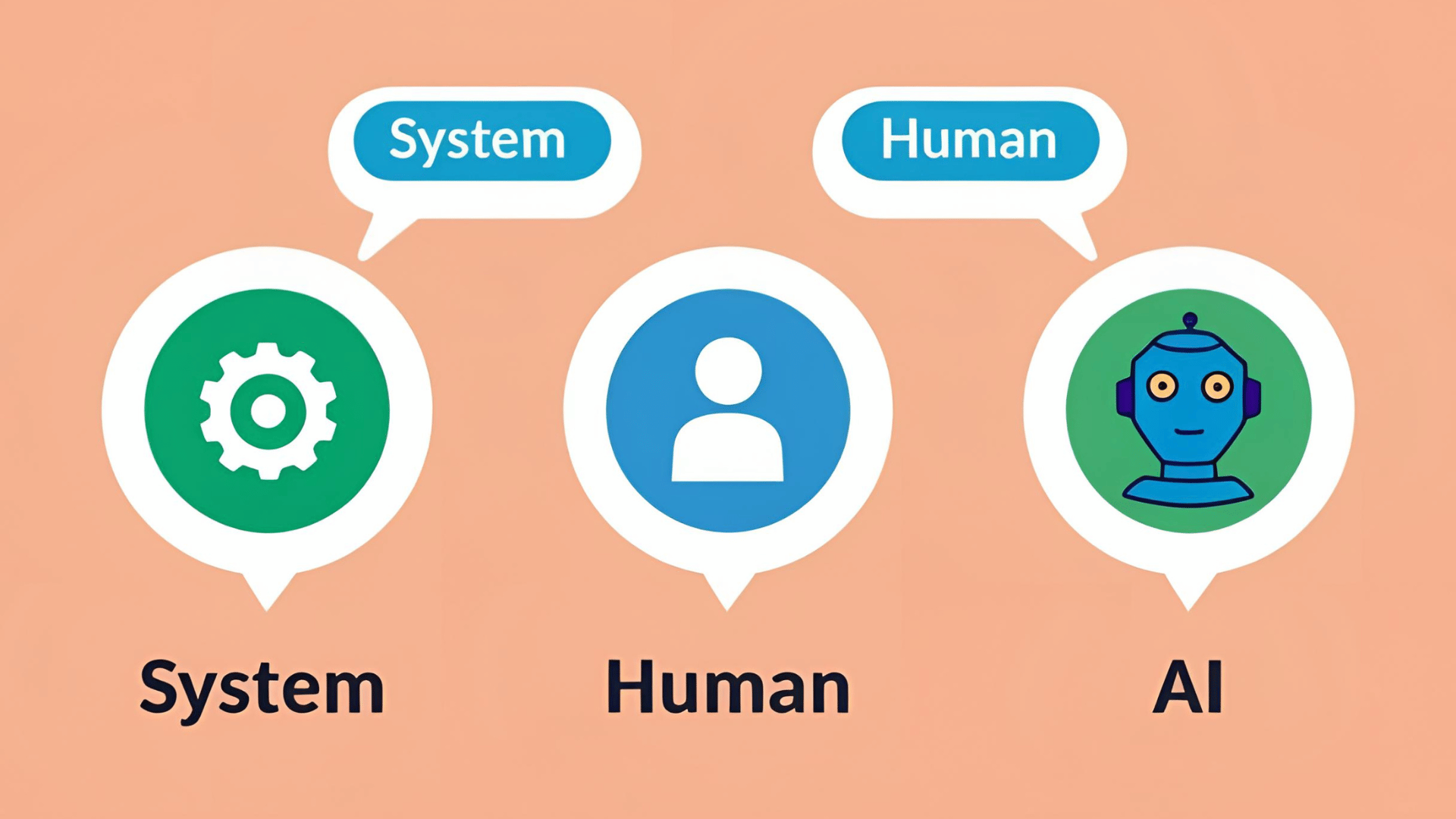
| ChatPromptTemplate | แบบฟอร์มคำสั่งที่ระบุว่า AI จะมี “บทบาทอะไร” และจะตอบ “คำถาม” ยังไง |
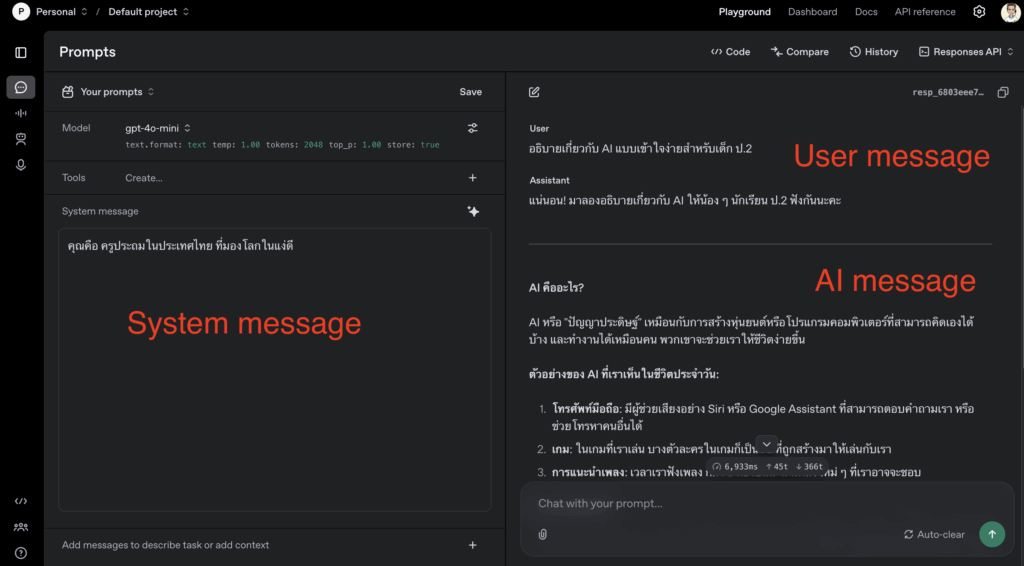
| System Message | ข้อความเบื้องหลังที่กำหนดพฤติกรรมของ AI |
| Human Message | ข้อความที่ผู้ใช้งานส่งเข้ามา เช่น “ปีที่ก่อตั้งบริษัทคือเมื่อไร?” |
🔧 ขั้นตอนการสร้างระบบถาม–ตอบ (RAG Chain)
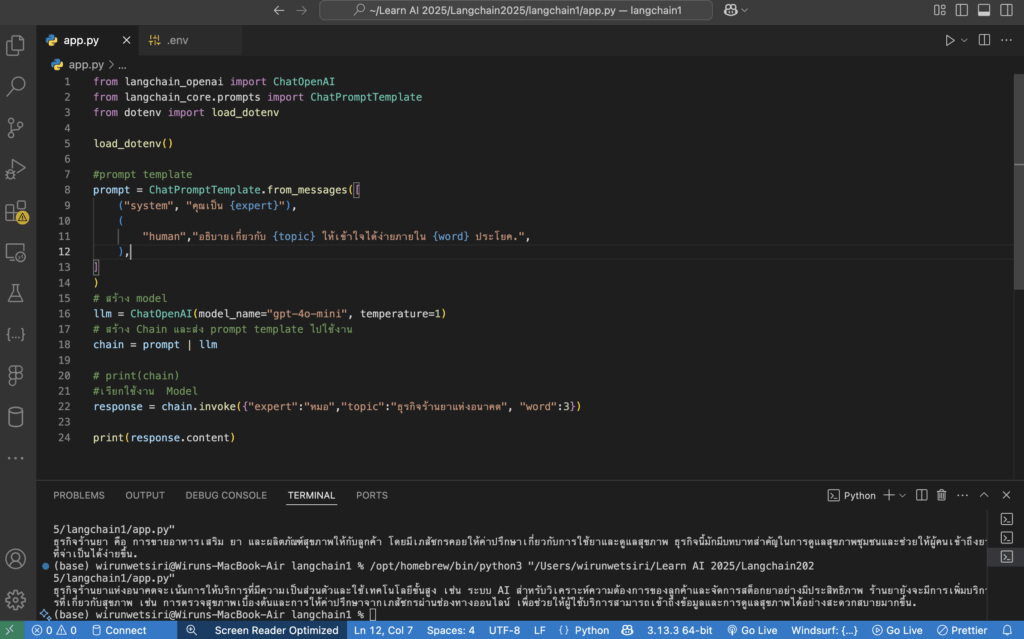
✅ 1. ออกแบบ Prompt Template
ChatPromptTemplate.from_messages([
SystemMessage(content="ใช้ข้อมูลจากเอกสารในการตอบคำถามอย่างสุภาพและกระชับ"),
HumanMessage(content="คำถาม: {question} \nข้อมูลที่เกี่ยวข้อง: {context}")
])
💬 System Message: บอกให้ AI ตอบ “จากเอกสาร” และตอบอย่างสุภาพ
💬 Human Message: กรอบคำถาม + ข้อมูลที่ AI จะใช้ตอบ
✅ 2. สร้าง AI Model (LLM)
ChatOpenAI(model="gpt-4-mini")
ใช้โมเดล GPT ที่เราตั้งค่าไว้ เช่น GPT-3.5 หรือ GPT-4-mini
จะทำหน้าที่ “คิดคำตอบ” จากสิ่งที่เราป้อนเข้าไป
✅ 3. สร้าง Retriever
retriever = vectorstore.as_retriever()
ดึงข้อมูลที่เกี่ยวข้องจากฐานข้อมูลเวกเตอร์ โดยเทียบกับคำถามที่ถามเข้ามา
✅ 4. สร้าง Chain
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
อธิบาย:
"context"ดึงข้อมูลจาก Vector Store ด้วย retriever"question"รับคำถามโดยตรงจากผู้ใช้- แล้วป้อนทั้งหมดเข้า Prompt → AI Model → แสดงผล
✅ 5. เรียกใช้งาน Chain
result = chain.invoke("ผู้ก่อตั้งบริษัทคือใคร")
print(result)
เราใส่คำถามไปแบบธรรมดา แต่เบื้องหลัง AI จะไป “ค้น + สรุป + ตอบ” ให้เอง
🔍 ตัวอย่างคำถามที่เราทดสอบในคลิป
| คำถาม | คำตอบที่ AI ตอบกลับ |
|---|---|
| ข้อมูลสำคัญในเอกสารมีอะไรบ้าง? | ชื่อบริษัท ABC, จำหน่ายของเล่นและหนังสือ, ผู้ก่อตั้ง, ที่อยู่, อีเมล ฯลฯ |
| ผู้ก่อตั้งบริษัทคือใคร? | กล้องรัชยาม ค่ะ |
| มีสินค้าอะไรบ้าง? | ของเล่น, โมเดล, ตุ๊กตา, บริการพรีออเดอร์ ฯลฯ |
✨ คำตอบทั้งหมดเป็นมิตร และมีคำลงท้ายแบบสุภาพ (ค่ะ / ครับ) ตามที่เรากำหนดใน System Message
🧭 Workflow โดยรวม
| ขั้นตอน | คำอธิบาย |
|---|---|
| Load | โหลดไฟล์เอกสาร |
| Split | แบ่งข้อความเป็นส่วนย่อย |
| Embed | แปลงเป็นเวกเตอร์ |
| Store | เก็บในฐานข้อมูลเวกเตอร์ |
| Retrieve | ดึงข้อมูลที่เกี่ยวข้องจาก Store |
| Prompt | สร้างคำสั่งให้ AI เข้าใจ |
| Model | ส่งข้อมูลให้โมเดลประมวลผล |
| Output | ได้คำตอบเป็นข้อความ |
🤔 ประโยชน์ของ RAG Chain คืออะไร?
- ✅ ทำให้ AI ตอบคำถามจากเอกสารภายในองค์กรได้
- ✅ ลดปัญหา “ตอบผิด” หรือ Hallucination
- ✅ ไม่ต้องเทรนโมเดลใหม่ แค่โหลดเอกสารใหม่ก็ใช้ได้เลย
- ✅ เหมาะสำหรับสร้าง Chatbot ถาม–ตอบภายในองค์กร เช่น
- ฐานข้อมูลสินค้า
- คู่มือการใช้งาน
- นโยบายบริษัท